3D Human Pose Estimation

Human Pose Estimation is a widely researched topic in Deep Learning. Its main idea is detecting locations of people’s joints, which form a “skeleton”. It has applications in human action recognition, motion capture, fun mobile applications, sport, augmented and virtual reality, robotics, etc.

In 2D there many multi-person Pose Estimation models with a good performance, described in this blog, many of which are realtime [1–4]. There are two major approaches: bottom-up (first detect body joints and then group them to get a person’s pose) and top-down (detect people first and execute a single-person pose estimation for all detections). COCO and MPII datasets are mainly used for 2D benchmarks.

Research on 3D Human Pose is less mature in comparison with the 2D case. There are two main approaches: first to estimate a 2D pose and then reconstruct a 3D pose or to regress a 3D pose directly. Research on multi-person 3D pose estimation is currently somewhat limited, primarily due to lack of good datasets. Most works report results on the Human3.6 dataset, which is the main dataset for single-person 3D pose performance comparison. It consists of multi-view videos of a single person in a room, whose pose is captured with the OptiTrack motion capture system.
Want to read this story later? Save it in Journal.
Most researchers concentrate on reconstructing a 3D pose from a single image and few of them look at multi-view. Some take into account depth in addition to an RGB image. Most works consider a single frame and few take time continuity constraint into account. Despite that 3D pose estimation is, in general, more computationally intensive, many 3D pose models are realtime. Most models use supervision, but there are few models, which are semi-supervised or fully self- unsupervised. Several models with the best performance will be described below in more details.
Single-person 3D pose
Most works for estimating human pose for a single person use a single image/video. Despite of the ambiguity in the depth dimension, models trained on 3D ground truth (GT) show pretty good performance for the case of a single person without occlusions. Similarly to humans, a neural network can learn to predict depth from a mono image in case it has already encountered similar scenes, which is demonstrated in the recent research on depth estimation.
Martinez’s et al. [5] baseline model, which is a fully-connected network with residual connections, takes as an input 2D pose from an off-the-shelf stat-of-the-art a 2D detector [1–4] and predicts a 3D pose with a regression loss from a single image. Interestingly, this simple model has a pretty good performance on Human3.6: Mean per Joint Position Error (MPJPE) (protocol 1) is 63 mm. Since the network is lightweight, if the 2D pose estimation is realtime, the full model is realtime as well.

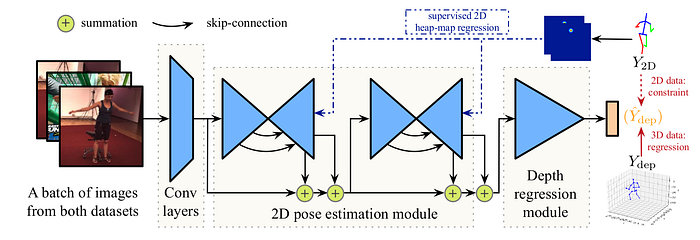
Zhou et al. [6], on the other hand, regress both 2D and 3D poses simultaneously and reaches similar performance to Martinez: MPJPE 65 mm on Human3.6. Zhou adopts a common approach for 2D pose estimation- an HourGlass network [1], which outputs heatmaps for every joint. The loss is an L2 distance between the predicted heatmaps and the GT, rendered through a Gaussian kernel. Depth is regressed directly. In addition, there is a 3D geometric constraint loss, based on the fact that ratios between bone lengths remain relatively fixed in a human skeleton, allowing to extend the 3D pose estimations to images in the wild. The model is realtime (25 FPS on a laptop with Nvidia GTX 960).
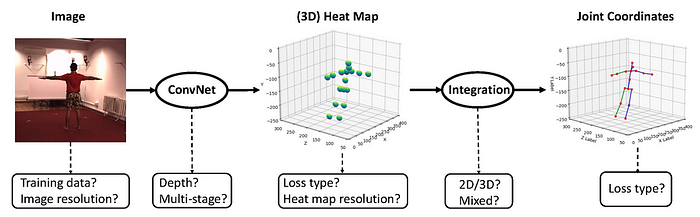
Sun et al. [7] use integral regression, instead of an L2 regression, for joint 2D/3D pose estimation, which is the integration of all locations in the heat map weighted by their probabilities. It is differentiable, efficient, and
compatible with any heat map-based methods. Since integral regression is simple and non-parametric, it adds a negligible overhead in computation and memory, leaving a realtime base model to stay realtime but improving performance. The authors experiment with several backbones: HourGlass [1] and Resnet18, 50 and 101. Integral regression with Resnet50 achieves the best performance on Human3.6: MPJPE 41 mm.
Mehta’s et al. [8] VNect regresses jointly 2D and 3D joint positions in a temporally consistent manner by adopting a model-based kinematic skeleton fitting. To have the 3D pose prediction linked more strongly to the 2D appearance in the image, the 2D heatmap formulation is extended to 3D using three additional location-maps Xj , Yj , Zj per joint j, and the xj, yj and zj values are read off from their respective location-maps at the position of the maximum of the corresponding joint’s 2D heatmap Hj. The L2 regression loss is weighted with respective 2D heatmap GT. VNect achieves 81 mm MPJPE on Human3.6 with ResNet50 as a backbone. It is realtime: 30 FPS on Titan X.

Pavllo et al. [9] start with predicted 2D poses from HourGlass [1], Mask R-CNN [2] or CPN [4] from N frames (and M views during training only) as an input to a small network with 1D dilated temporal convolutions and predicts 3D pose for either the middle (symmetric convolutions) or the next frame (causal convolutions). A model with CPN backbone achieves a very good performance of 47 mm MPJPE on Human3.6. The 1D convolutional network is tiny and runs very fast, achieving realtime performance given the 2D pose backbone is realtime.
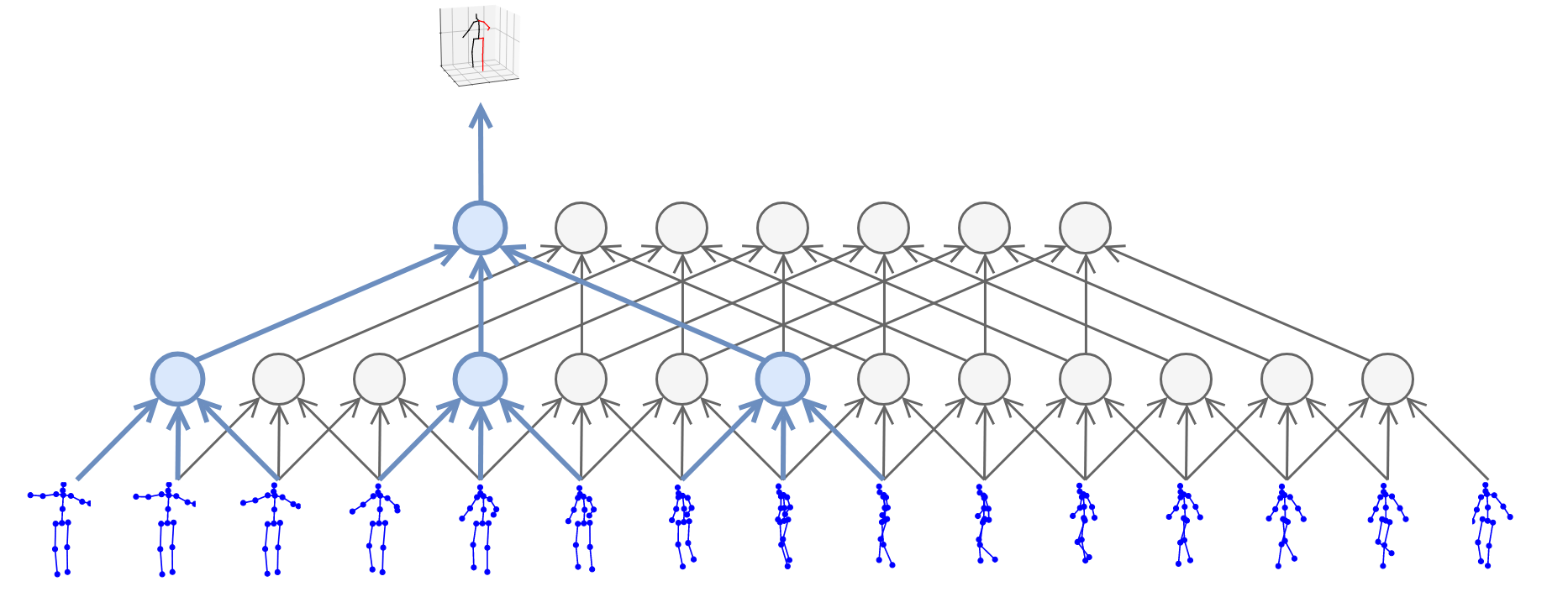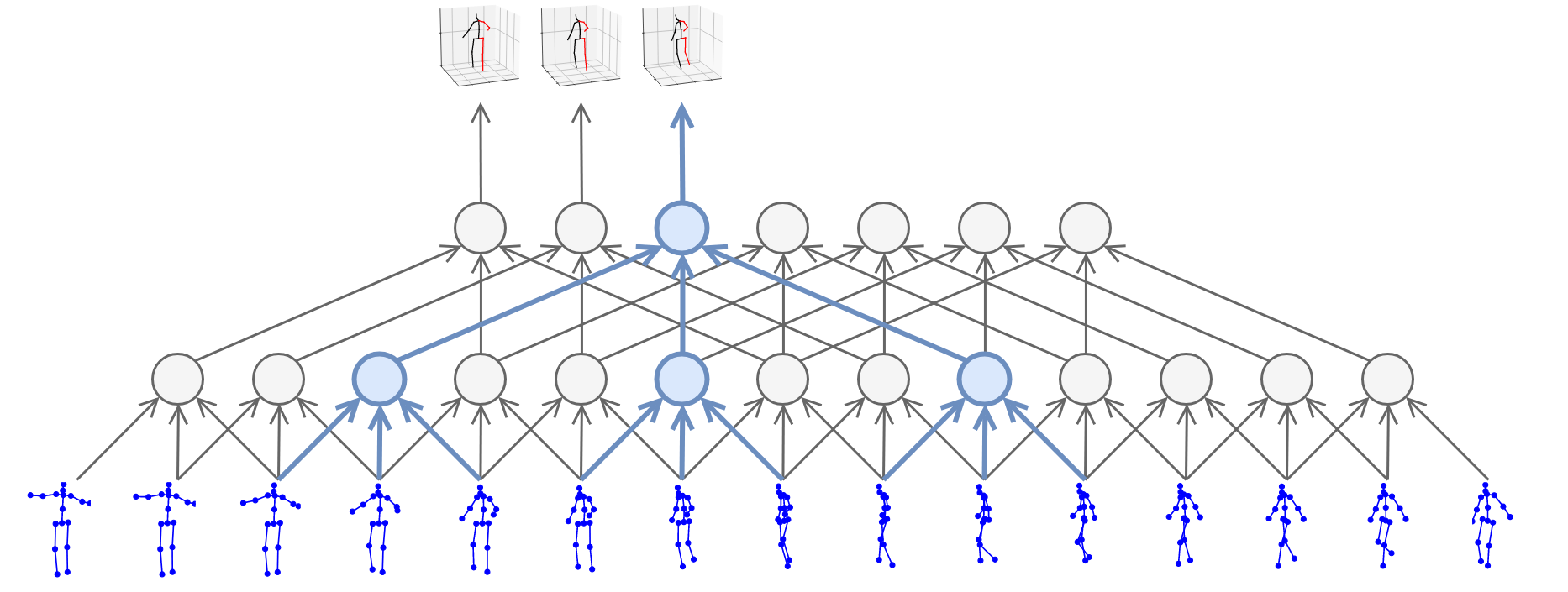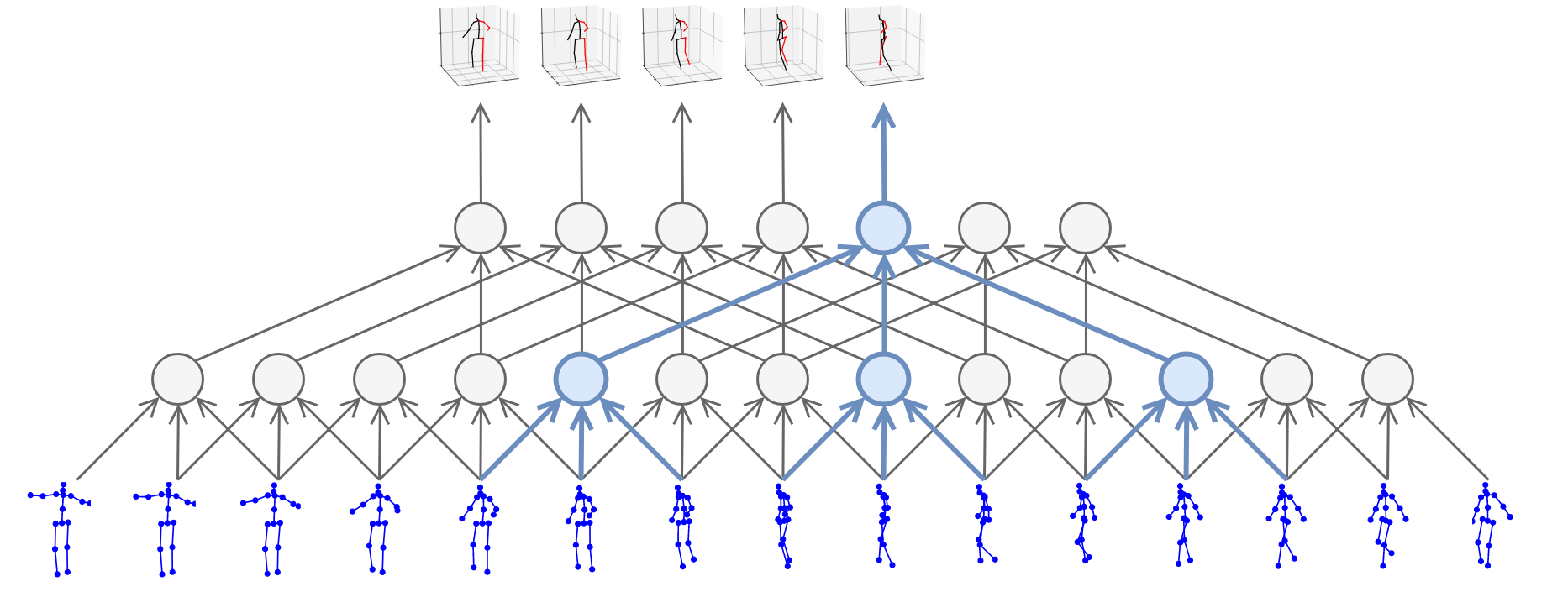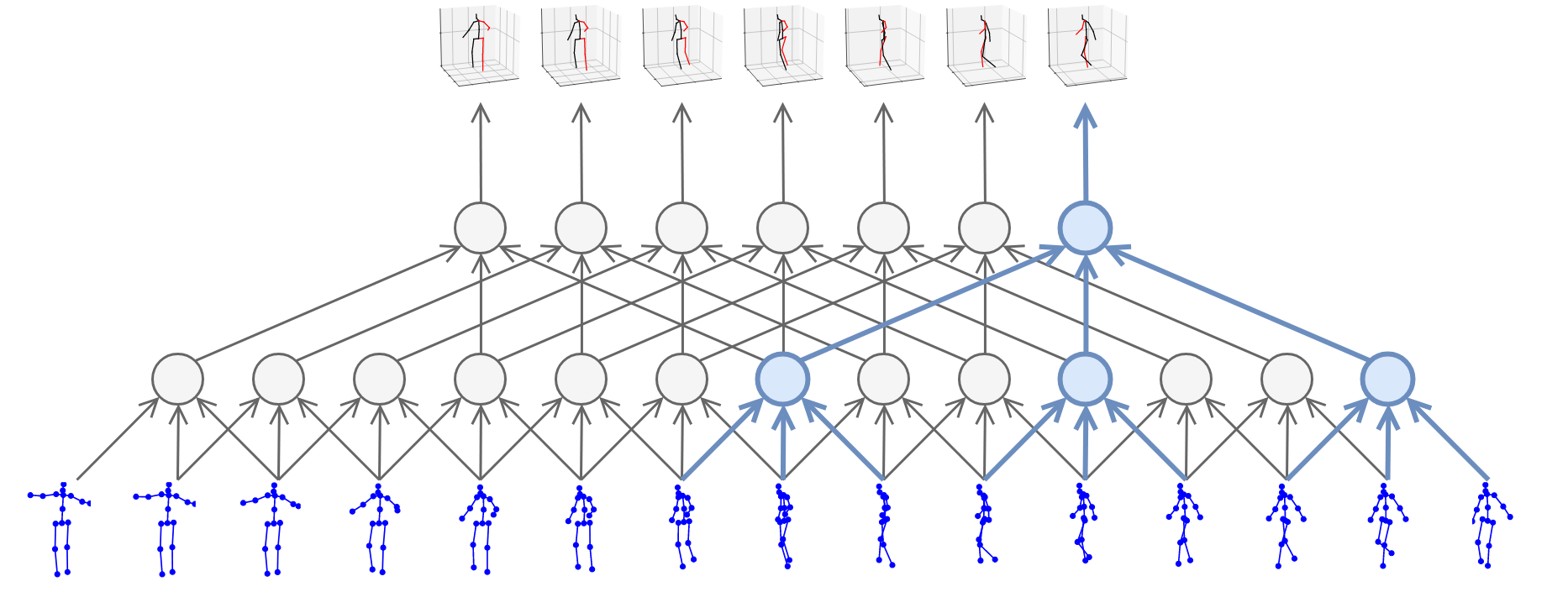
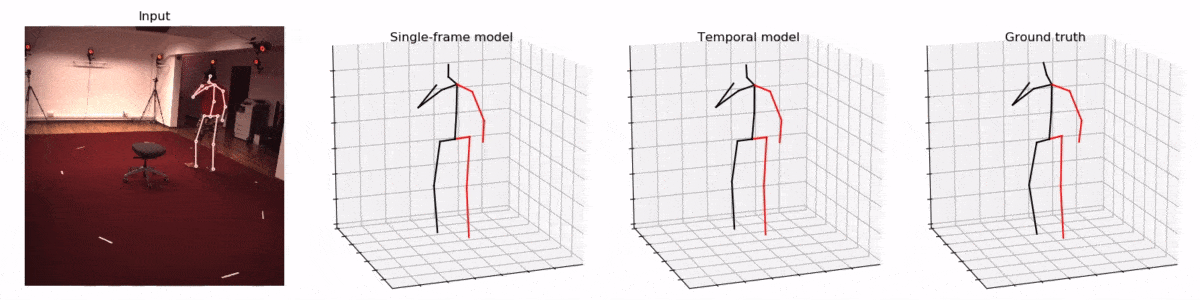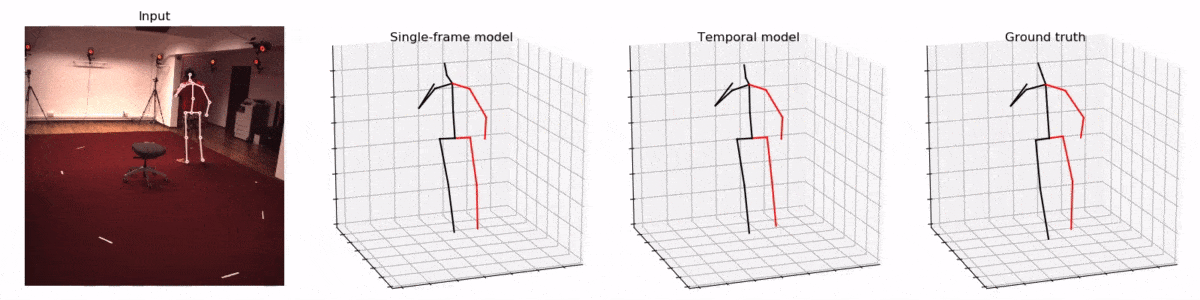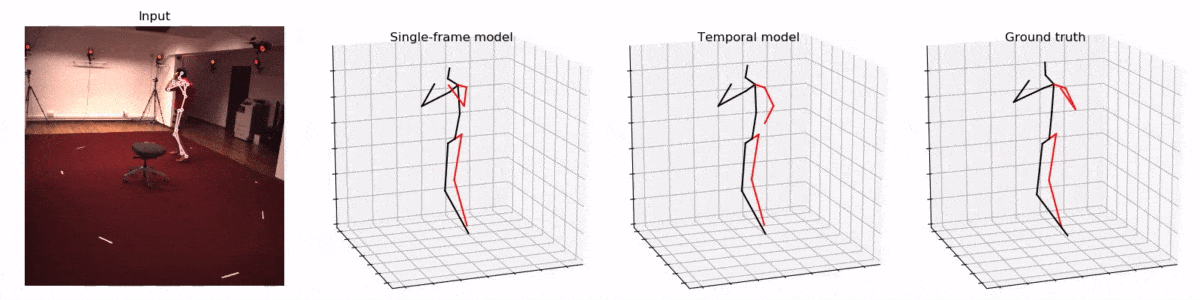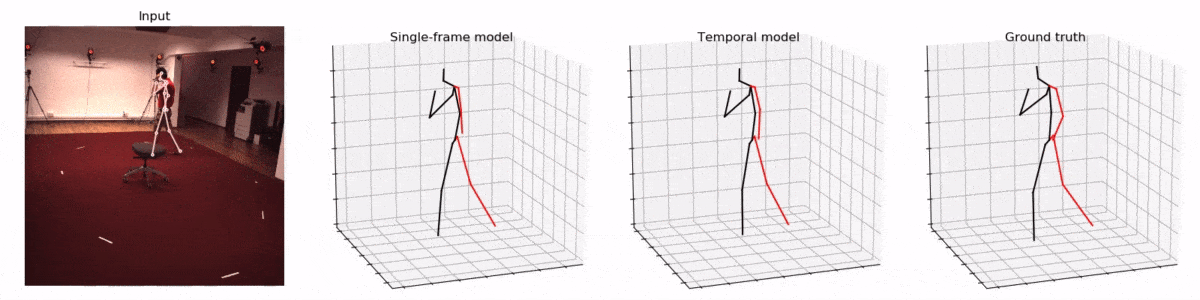
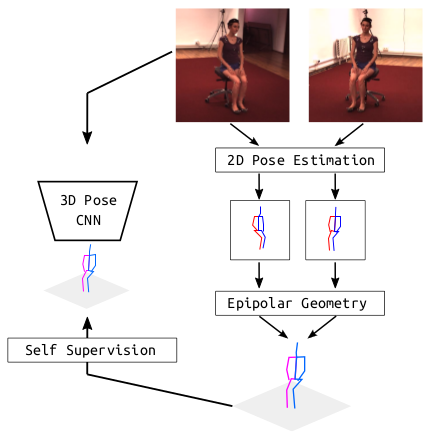
Kocabas’ et al. [10] EpipolarPose infers 3D pose from single images using a fully self-supervised approach, but it is trained with multi-view images. The network with a ResNet50 backbone, pretrained on the MPII dataset, outputs volumetric heatmaps, from which a 2D pose for two or more views is inferred. A 3D pose pseudo-GT is obtained with the help of polynomial triangulation, which is used as a supervision signal in a smooth L1 loss. The model uses body joints as calibration targets when a camera’s extrinsic parameters are unknown, which is often the case. EpipolarPose (with refinement) achieves 61 mm MPJPE on Human3.6, which is an excellent result for an unsupervised model.
Zimmermann et al. [11] use as an input mono images with depth from Kinnect and directly regresses 3D pose with a 3D convolutional network. Since there is no depth dimension in the Human3.6 dataset, it is hard to compare the results of the network. For training, the authors use a Multi View Kinnect Dataset.

Multi-person 3D pose
The main challenge in multi-person 3D pose estimation is occlusions. In addition, unfortunately, there are almost no annotated multi-person 3D pose datasets like the Human3.6 dataset. Most multi-person datasets either do not have good GT or are not realistic:
- Panoptic Dataset (480 calibrated cameras, no GT)
- Campus Dataset (5 calibrated cameras, GT from triangulation)
- Shelf Dataset (3 calibrated cameras, GT from triangulation)
- MuPoTS-3D Dataset (test set with GT from markerless motion capture)
- MuCo-3DHP Dataset (synthesized dataset)
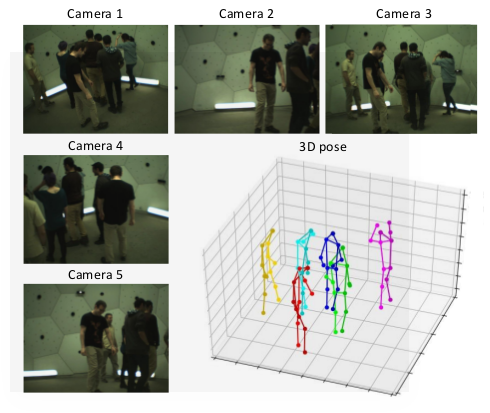
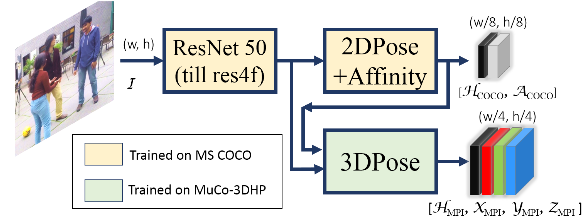
Mehta et al. [12] introduce a single-shot multi-person 3D pose estimation model from a single image. The authors use occlusion-robust posemaps (ORPM), which enable full body pose inference even under strong partial occlusions by other people and objects. ORPM outputs a fixed number of maps, which encode the 3D joint locations of all people and 3D pose for an arbitrary number of people is inferred using body part associations. The backbone is Resnet50. MuCo-3DHP dataset is used for training and MuPoTs-3D for evaluation with 70% detection accuracy (3DPCK within a 15 cm ball) reported. Performance on Human3.6 is reported as well: 70 mm MPJPE.
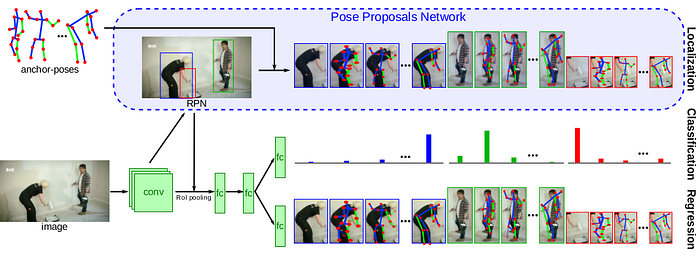
Rogez’s et al. [13] model estimates joint 2D/3D human poses of multiple people simultaneously from a single image and has a Localization-Classification-Regression architecture (LCR-Net). The main component is the pose proposal generator that suggests candidate poses at different locations in the image out of 100 anchor poses and a classifier scores the different pose proposals. A smooth L1 regression then refines pose proposals both in 2D and 3D. All the three stages share the convolutional feature layers and are trained jointly. The final pose estimation is obtained by integrating over neighboring pose hypotheses. The model is evaluated on the MuPoTs-3D dataset and reports 74% accuracy. Performance on Human3.6 is reported as well: 54 mm MPJPE.
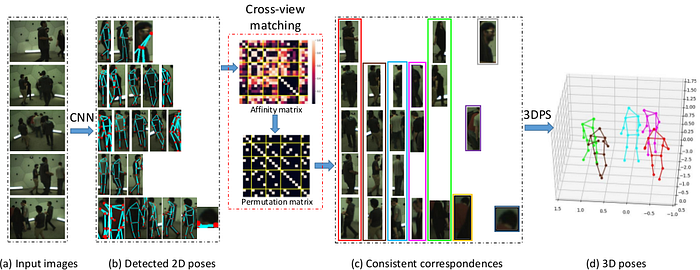
Dong et al. [14] use as an input multi-view images and estimates first multi-person 2D poses from CPN [4] in every view. Matching detected persons across multiple views is done by calculating affinity scores by using appearance similarity (Euclidean distance between descriptors from a pretrained re-ID network) and geometric compatibility (point-to-line distance between a joint and a corresponding epipolar line). Given the estimated 2D poses of the same person in different views, the 3D pose can be reconstructed by triangulation, but the gross errors in 2D pose estimation may largely degrade the reconstruction. In order to fully integrate uncertainties in 2D pose estimation and incorporate the structural prior on human skeletons, 3D Pictorial Structure (3DPS) model is used. The reported performance on the Campus dataset is 96 percents of correctly estimated parts (PCP) and on the Shelf dataset 97 PCP . Panoptic dataset is used for qualitative evaluation. It is realtime (without 3DPS) on GTX 1080Ti.
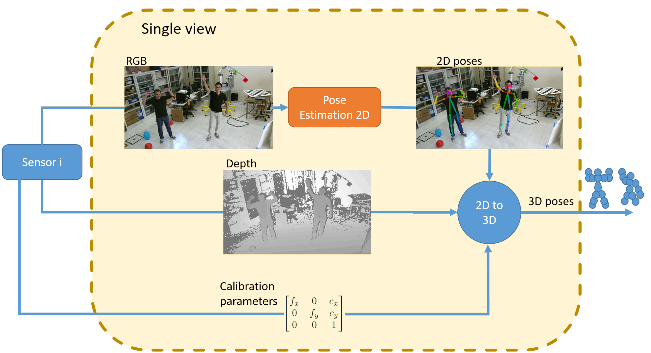
Carraro et al. [15] estimate 3D poses from multi-view images with depth from calibrated Kinnect v2 cameras. An input to the network is a multi-person 2D poses from OpenPose [3] for every view, which is lifted to 3D by incorporating the depth information. Views from multiple cameras are then fused together by means of multiple Unscented Kalman Filters. The authors recorded and annotated their own dataset. The model runs in realtime.
In summary, single-person 3D pose estimation from a single image has achieved a very good performance with less than 4 cm error on joint’s coordinates estimation on average. However, there is still a lot of space for research in the field of 3D human pose, since a complete solution, which is multi-person, multi-view, temporally consistent and realtime is missing. There are many more papers on 3D pose estimation than what I have covered here, a list of which can be found here, here and here. Other blogs about human pose estimation can be found here and here.
References:
[1] Newell et al. “Stacked Hourglass Networks for Human Pose Estimation” (2016) code
[2] He et al. “Mask R-CNN” (2017) code
[3] Cao et al. “OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields” (2018) code
[4] Chen et al. “Cascaded Pyramid Network for Multi-Person Pose Estimation” (2017) code
[5] Martinez et al. “A simple yet effective baseline for 3d human pose estimation” (2017) code
[6] Zhou et al. “Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach” (2017) code
[7] Sun et al. “Integral Human Pose Regression” (2017) code
[8] Mehta et al. “VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera” (2017) code
[9] Pavllo et al. “3D human pose estimation in video with temporal convolutions and semi-supervised training” (2018) code
[10] Kocabas et al. “Self-Supervised Learning of 3D Human Pose using Multi-view Geometry” (2019) code
[11] Zimmermann et al. “3D Human Pose Estimation in RGBD Images for Robotic Task Learning” (2018) code
[12] Mehta et al. “Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB” (2017) code
[13] Rogez et al. “LCR-Net++: Multi-person 2D and 3D Pose Detection in Natural Images” (2018) code (LCR_Net)
[14] Dong et al. “Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views” (2019) CVPR2019 code
[15] Carraro et al. “Real-time marker-less multi-person 3D pose estimation in RGB-Depth camera networks” (2017) code
More from Journal
There are many Black creators doing incredible work in Tech. This collection of resources shines a light on some of us:
